# Java Interview Questions List
# 1.1 核心Java面试问题系列 - 第一部分
Core Java Interview Questions – Part 1
# 如何在Java中创建不可变对象?使用不可变对象的收益是什么?
不可变类是指一旦创建,其状态就不能更改的类。
在这里,对象的状态本质上是指存储在实例变量中的值,无论它们是基本类型还是引用类型。
要使类不可变,需要遵循以下步骤:
- 不提供 setter方法,避免对象的字段被修改
- 所有字段声明为final和private
- 不允许子类重写父类方法 最简单的方法是将类声明为final,以限制子类继承父类。 更好点的方式是将构造方法设为private,同时通过工厂方法来创建实例。
- 如果域包含其他可变类的对象,也要禁止这些对象被修改:
(1)不提供修改可变对象的方法
(2)不要共享指向可变对象的引用 不要存储那些传进构造方法的外部可变对象的引用;如果需要,创建拷贝,保存指向拷贝的引用。
类似的,在创建方法返回值时,避免返回原始的内部可变对象,而是返回可变对象的拷贝。
参考:A Strategy for Defining Immutable Objects 参考:How to create immutable class in Java
不可变类的优势:
- 创建、测试和使用都很简单。
- 线程安全,没有同步问题
- 不需要拷贝构造方法
- 不需要实现Clone方法
- 可以缓存类的返回值,允许hashCode使用惰性初始化方式
- 不需要防御式复制
- 适合用作Map的key和Set的元素(因为集合里这些对象的状态不能改变)
- 类一旦构造完成就是不变式,不需要再次检查
- 总是“failure atomicity”(原子性失败): 如果一个不可变对象抛出异常,它从不会保留一个烦人的或者不确定的状态
# Java是引用传递还是值传递?
Java 规范说,Java没有引用传递,所有都是值传递。
Java是值传递而不是引用传递
如果Java是引用传递,我们应该可以像C语言一样交换对象,而这在Java中是做不到的。
向方法传递实例时,它的内存地址会被1比特1比特的复制到一个新的引用变量中,它们都指向相同的实例。
但是如果你在方法内改变这个引用,原始引用不会改变。
如果是引用传递,原始引用也会改变。
参考:Java Pass-by-Value vs. Pass-by-Reference
注:
值就直接保存在变量中,而String等是引用类型,变量中保存的只是实际对象的地址。
一般称这种变量为"引用",引用指向实际对象,实际对象中保存着内容。
# finally块的用途是什么?finally块是否可以确保被调用?如果不能,何时不被调用?
try块退出时,finally块始终执行,这样可以确保即使发生异常,finally块也会被执行。
finally 不仅仅对异常处理有用,它使得程序员可以避免因return,continue或break而意外绕过执行清理代码。
将清理代码放在finally块中是一个好习惯,即使可能没有异常发生。
如果在执行try或catch代码时JVM退出,则finally块可能不会执行。 同样,如果执行try或catch代码的线程被中断或杀死,即使整个应用程序继续运行,finally块也可能不会执行。
# 为什么有两个Date类?一个在java.util包中,另一个在java.sql中?
java.util.Date表示日期和时间。
java.sql.Date仅表示日期,没有时间部分,java.sql.Time,表示时间。
java.sql.Date是java.util.Date的子类(扩展)。
因此,java.sql.Date 做了一些改变:
toString()生成字符串形式不同:yyyy-mm-dd;
静态valueOf(String)方法,用于从具有上述表示形式的字符串中创建日期;
不建议使用小时,分钟和秒的 getters 和 setter 方法已经废弃。
java.sql.Date类与JDBC一起使用,它不应有时间部分,即小时,分钟,秒,毫秒应为零,但是并不强制。
# 什么是标记接口?
标记器接口模式是计算机科学中的一种设计模式,与提供有关对象的运行时类型信息的语言一起使用。
它提供了一种将元数据与一个类相关联的方法,其中该语言对该类元数据没有明确的支持。
在Java中,表现为不包含方法的接口。
在Java中使用标记接口的一个很好的例子是Serializable接口。
一个类实现此接口,以标识可以将其非 transient 数据成员写入字节流或文件系统。
标记接口的主要问题是接口为实现类定义了契约,该契约会被所有子类继承,这意味着在子类中你只能实现标记接口。
如果创建的子类不想被序列化(可能是因为它依赖于transient状态),则必须诉诸显式抛出 NotSerializableException。
# 为什么Java中的main函数被声明为public static void?
为什么是public?
main方法是public,任何一个想要启动应用程序的对象在任何地方都可以访问它。
为什么是静态的?
假设main方法不是静态方法,要调用任何方法,需要它的一个实例。
众所周知,Java可以有重载的构造函数,JVM 就没法确定调用哪个 main 方法。
补充:
静态方法和静态数据加载到内存就可以直接调用而不需要像实例方法一样创建实例后才能调用,
如果 main 方法是静态的,那么它就会被加载到 JVM 上下文中成为可直接执行的方法。
为什么返回值为void?
这样就不会返回一个无用的返回值给JVM。
应用程序要与调用过程进行通信的唯一一件事是:正常终止或异常终止。
使用System.exit(int)已经可以做到这一点。 非零值表示异常终止,否则一切正常。
# 使用new()和字面意思(直接双引号引用)创建字符串有什么区别?
使用new()创建String时,会在堆中创建并添加到字符串池中,而使用字面意思创建时,仅在字符串池(存在于堆的Perm区)中创建。
# String中的substring()如何工作?
Java中的字符串与其他编程语言一样,是一串字符。
这个字符序列在下面的变量中维护:
/** The value is used for character storage. */
private final char value[];
要在不同情况下访问此数组,请使用以下变量:
/** The offset is the first index of the storage that is used. */
private final int offset;
/** The count is the number of characters in the String. */
private final int count;
每当我们从任何现有的字符串实例创建子字符串时,substring()方法都只会设置offset和count变量的新值,内部char数组不变。
如果不小心使用substring()方法,则可能是内存泄漏的原因。
注:
JDK1.6 的实现有可能导致内存泄露,引用同一个字符数组会导致GC无法回收空间,因为即使原字符串做了释放,但子字符串的引用仍在。
内存泄露 实现原理 从这里看,JDK7 之后实现是会产生新的字符数组的。
# 解释HashMap的工作原理,如何解决冲突?
HashMap有一个内部类Entry:
static class Entry<k ,V> implements Map.Entry<k ,V>
{
final K key;
V value;
Entry<k ,V> next;
final int hash;
...//More code goes here
}
当需要存储键值对时:
- 首先,检查key是否为null,是,则值存储在table[0]位置,因为null的Hash 码 始终为0。
- 接下来,对key 使用Hash Code 通过调用hashCode()计算哈希值,该哈希值用于计算数组中用于存储Entry对象的索引。
- 此时,调用indexFor(hash, table.length)函数来计算精确索引位置。
- 接下来是主要部分。
现在,我们知道两个不相等的对象可以有相同的哈希码值,两个不同的对象将如何存储在相同的数组位置[称为bucket],答案是LinkedList。
Entry类有一个next属性,这个属性总是指向链表中的下一个对象。
因此,在发生冲突时,Entry对象以LinkedList的形式存储。
当需要在特定索引中存储Entry对象时,HashMap检查是否已经存在,如果没有,则存储在此位置。
如果已经有一个对象位于索引上,则检查它的next属性。
如果为空,则当前Entry对象将成为LinkedList中的下一个节点。
如果next变量不为null,则遍历,直到next变量是null为止。
如果我们添加另一个值对象,其键值与前面输入的键值相同。从逻辑上讲,它应该替换旧值。是怎么做到的呢?
在确定Entry对象的索引位置之后,当遍历LinkedList时,HashMap对每个Entry对象的键对象调用equals()方法。
LinkedList中的所有这些HashMap对象都具有类似的哈希码,但equals()方法将测试是否真正相等。
如果key.equals(k)为真,那么两个键都被视为相同的键对象,此时会做Entry对象替换。
通过这种方式, HashMap 确保键的惟一性。
注:
put 的思路
- 对key的hashCode()做hash,然后再计算index;
- 如果没碰撞直接放到bucket里;
- 如果碰撞了,以链表的形式存在buckets后;
- 如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树;
- 如果节点已经存在就替换old value(保证key的唯一性)
- 如果bucket满了(超过load factor*current capacity),就要resize。
get 的思路
- bucket里的第一个节点,直接命中;
- 如果有冲突,则通过key.equals(k)去查找对应的 Entry
(1) 若为树,则在树中通过key.equals(k)查找,O(logn);
(2) 若为链表,则在链表中通过key.equals(k)查找,O(n)。
# 接口和抽象类之间的区别?
- Java接口中声明的变量默认是final,抽象类可以包含非final变量。
- Java接口是隐式抽象的,接口中不能有实现,Java抽象类可以拥有实现默认行为的实例方法。
- 默认情况下,Java接口的成员是公共的,Java抽象类可以具有通常的类成员样式,如private或abstract等。
- Java接口应使用关键字implements实现;抽象类使用关键字extends扩展。
- Java类可以实现多个接口,但只能扩展一个抽象类。
- 接口是不能实例化;Java抽象类也不能实例化,但如果存在main(),则可以调用它。
从Java 8开始,可以在接口中定义默认方法。 - 抽象类比interface稍微快一些,因为interface在调用Java中任何被覆盖的方法之前都要进行搜索(肯能有多个实现)。
# 什么时候重写hashCode()和equals()?
hashCode()和equals()方法已经在Object类中定义,Object类是java对象的父类。
因此,所有Java对象都继承这些方法的默认实现。
hashCode()方法用于获取给定对象的唯一整数。
当需要将该对象存储在诸如散列表等数据结构中时,这个整数用于确定bucket位置。
默认情况下,对象的hashCode()方法返回存储对象的内存地址的整数表示。
equals()方法,顾名思义,用于验证两个对象的相等性。默认实现只是检查两个对象的对象引用,以验证它们是否相等。
请注意,每当重写equals()方法时,通常都需要重写hashCode方法,
以便维护hashCode()方法的通用契约,该契约规定equal对象必须具有相等的哈希码。
- equals()必须定义相等关系(它必须是自反的、对称的和传递的)。
此外,它必须是一致的(如果对象没有被修改,那么它必须一直返回相同的值),o.equals(null)必须总是返回false。 - hashCode()也必须是一致的(如果没有根据equals()修改对象,则必须始终返回相同的值)。
这两个方法之间的关系是:
当a.equals(b)为真时,那么a.hashCode()必须与b.hashCode()相同。
# 1.1 核心Java面试问题系列 - 第二部分
# 为什么要避免使用finalize()方法?
在回收内存之前,垃圾回收器线程会调用finalize()方法,但并不能保证finalize()一定被执行。
- finalize()方法并不像构造函数的机制,父类的构造方法默认被调用,而超级类的finalize()应该显式调用。
- 由 finalize() 方法抛出的任何异常都将被GC线程忽略,并且不会进一步传播,实际上,它不会被记录在日志文件中。
- 类中包含finalize()时,也会影响性能。
Joshua bloch在有效的Java(第2版)中说,在我的机器上,创建和销毁一个简单对象的时间约为5.6 ns。
添加终结器会将时间增加到2,400 ns,换句话说,使用 finalizers 创建和销毁对象要慢430倍。
注: finalize()方法
是一个Object类的方法,也就是说所有类都会继承这个finalize()方法,这个方法默认实现为空。
这个方法被用于在对象被回收之前做一些收尾工作,但是被执行是有条件的。
为什么要避免使用finalize方法?
- 行为不可预测
无法预测是否会被执行、无法预测执行是否完整。 - 延迟对象回收
使用finalize方法使得对象的回收变得“拖拖拉拉,不够干脆”。 - 可替代
大部分情况下,try - finally可以替代finalize方法。
# 为什么不应该在多线程环境中使用HashMap?它也会引起无限循环吗?
HashMap 没有采用同步机制,在多线程环境中存在线程安全问题。
HashTable 是线程安全的。
HashMap.get()可能导致无线循环:
# HashMap.get() 源码
public Object get(Object key) {
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
Entry e = table[i];
while (true) {
if (e == null)
return e;
if (e.hash == hash && eq(k, e.key))
return e.value;
e = e.next;
}
}
while(true){...}在多线程环境下,e.next可以以某种方式指向自身,这将导致无限循环。
可以在void transfer(Entry [] newTable)方法中发生,该方法在HashMap调整大小时调用。
do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
如果发生了调整大小的情况,同时其他线程试图修改map实例,则这段代码很容易产生上述情况。
避免这种情况的唯一方法是在代码中使用同步,更好的方法是使用线程安全的集合数据结构。
# 解释抽象和封装?有什么关系?
抽象可以表现为两种方式:
- 数据抽象
是一种创建复杂数据类型和只公开有意义的操作与数据类型交互的方法,在这种方法中隐藏所有的实现细节。 - 控件抽象
是识别所有此类语句并将其作为工作单元公开的过程。当我们创建一个函数来执行任何工作时,通常会使用此功能。
将类中的数据和方法与实现隐藏(通过访问控制)结合起来通常称为封装。结果是具有特征和行为的数据类型。
封装本质上有信息隐藏和实现隐藏。
–抽象更多地是关于“类可以做什么”。 [理念]
–封装更多地是关于“如何”实现该功能。 [实施]
# 接口和抽象类之间的区别?
- 一个类可以实现许多接口,但是只能有一个父类(抽象或非抽象)
- 接口不是类层次结构的一部分,不相关的类可以实现相同的接口。
当可以完全描述一个概念,即它可以做什么,而不需要指定它是如何做的,那么应该使用接口。
如果需要包含一些实现细节,那么需要在抽象类中实现。
是否有许多类可以用一个名词组合在一起,如果是这样,用这个名词创建一个抽象类,并继承它。
什么样的动词可以应用到我的类上,并且通常也可以被其他类使用? 为每个动词创建一个接口。
例如,所有的动物都可以喂养,因此我将创建一个名为IFeedable的接口,并让Animal实现它。
而只有狗和马可以很好地实现ILikeable,但有些则不行。
# StringBuffer 如何保存内存?
字符串被实现为不可变对象,JVM会分配一个与初始值长度相等的固定数组。
然后,将其视为JVM内部的常量,在不更改String值的情况下,可以大大节省性能。
但是如果修改String的内容,那么JVM会把原始String的内容复制到一个临时空间中,进行修改,
然后将这些更改保存到一段全新的内存中。
因此,在初始化后修改String值是比较昂贵的操作。
StringBuffer 在JVM内部实现为可动态增长的数组,这意味着修改操作都可以在现有内存中直接进行,
只有在需要时才分配新内存。
# 为什么在Object类而不是线程中声明了 wait and notify?
注:
- wait()、notify()和notifyAll()方法是本地方法,并且为final方法,无法被重写。
- 调用某个对象的wait()方法能让当前线程阻塞,并且当前线程必须拥有此对象的monitor(即锁,或者叫管程)
- 调用某个对象的notify()方法能够唤醒一个正在等待这个对象的monitor的线程,
如果有多个线程都在等待这个对象的monitor,则只能唤醒其中一个线程。
why ?
- wait 和 notify 不仅仅是普通方法或同步工具,更重要的是它们是 Java 中两个线程之间的通信机制,
同步和等待通知是两个不同的领域,不要把它们看成是相同的或相关的。
同步是提供互斥并确保 Java 类的线程安全,而 wait 和 notify 是两个线程之间的通信机制。 - 锁是在对象基础上提供的。
- Java 中的线程要进入同步块,需要等待锁,但并不知道哪些线程持有锁,而只是知道锁被某个线程持有,
并且他们应该等待取得锁, 而不是去了解哪个线程在同步块内,并请求它们释放锁定。 - Java 是基于 Hoare 的监视器的思想
在Java中,所有对象都有一个监视器。
线程在监视器上等待,为执行等待,我们需要2个参数:
一个线程
一个监视器(任何对象)
在 Java 设计中,线程不能被指定,它总是运行当前代码的线程。但是,我们可以指定监视器(这是我们称之为等待的对象)。
# 编写Java程序以在Java中创建死锁并修复死锁?
死锁
(1)循环等待
(2)非剥夺如何避免死锁
对代码访问共享资源的语句重新排序。
强迫其中一个线程释放资源。
# 如果 Serializable 类包含一个不可序列化的成员,该怎么办?如何解决?
在这种情况下,NotSerializableException 将在运行时抛出。
解决方法:
- 非序列化字段设置为 transient;
- 在writeObject()中,首先在流上调用defaultWriteObject()以存储所有非瞬态字段,
然后调用其他方法来序列化不可序列化对象的各个属性。 - 在readObject()中,首先在流上调用defaultReadObject()以读回所有非瞬态字段,
然后调用其他方法(对应于添加到writeObject的方法)来反序列化不可序列化的对象。
参考:
Java Serialization Tutorial
# 解释Java中的 transient 和 volatile 关键字?
transient 关键字 用于标识不被序列化的字段。
根据语言规范: 变量可以标记为transient,表示它们不是对象持久状态的一部分。
例如,可能拥有从其他字段派生的字段,并且只能通过编程来实现,而不是通过序列化来持久化状态。
volatile修饰符告诉JVM,访问该变量的线程必须始终将其变量私有副本与内存中的主副本协调一致。
这意味着每次线程要读取变量的状态时,它都必须刷新其本地内存状态并更新主内存中变量。
volatile在无锁算法中最有用。
volatile应该用于在多线程环境中安全地发布不可变对象。
声明一个像 public volatile ImmutableObject foo 这样的字段可以确保所有线程总是看到当前可用的值。
# Iterator 和 ListIterator 之间的区别?
可以使用Iterator遍历集合、列表或映射,但是ListIterator只能用于遍历列表。其他差异如下:
- Iterator 在Set和List接口中都有定义,ListIterator仅存在于List接口中(或实现类中)。
- ListIterator有add()方法,可以向List中添加对象,而Iterator不能。
- ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,
但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历,而Iterator就不可以。 - ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现,Iterator没有此功能。
- 都可实现删除对象,但是ListIterator可以实现对象的修改,set()方法可以实现,Iterator 仅能遍历,不能修改。
注:
Iterator接口定义了3个方法分别是hasNext(),next(),remove();
# 1.1 核心Java面试问题系列 - 第三部分
# 深拷贝与浅拷贝
# 什么是同步?类级别锁定和对象级别锁定?
同步与多线程有关,同步代码块同时只能由一个线程执行。
同步避免了由于共享内存视图不一致而导致的内存一致性错误。
当方法声明为 synchronized 时,该线程持有该方法对象的监视器。
如果另一个线程正在执行同步方法,则该线程将被阻塞,直到该线程释放监视器。
Java中的同步是使用 synchronized 关键字实现的。你可以在类中的方法或代码块上使用 synchronized 关键字。
关键字不能与类定义中的变量或属性一起使用。
对象级锁定 是当希望同步非静态方法或非静态代码块时的一种机制,以便只有一个线程能够在类的给定实例上执行代码块。
应该始终这样做,以确保实例级数据线程安全。
类级别锁定 防止多个线程进入运行时所有可用实例中的同步块。
这意味着,如果在运行时有100个DemoClass实例,那么每次只有一个线程能够在任何一个实例中执行demoMethod(),而其他所有实例将为其他线程锁定。
为了使静态数据线程安全,应该始终这样做。
# sleep()和wait()之间的区别?
# 可以给 this 引用变量赋值null吗?
不可以。
在java中,赋值语句的左边必须是一个变量。
this 是一个表示当前实例的特殊关键字,它不是变量。类似地,null也不能分配给 super 等类似关键字。
# &&和&之间的区别?
&是位运算,&&是逻辑运算
&双方都参与计算。
&& 先评估计算对象的左侧,如果是,则继续并评估右侧。
# 如何重写equals() 和 hashCode() 方法?
参考:
Java hashCode() and equals() – Contract, rules and best practices
Java hashCode()和equals()的契约、规则和最佳实践
hashCode()在运行时为对象返回一个惟一的整数值,默认情况下,hashCode()方法返回存储对象的内存地址的整数表示。
当需要将该对象存储在诸如HashTable 之类的数据结构时,这个整数用于确定bucket位置。
equals(Object otherObject),它的默认实现只是检查两个对象的对象引用来验证它们的相等性。
默认情况下,当且仅当两个对象存储在相同的内存地址时,它们是相等的。
- hashCode() and equals() 之间的契约
每当重写equals()方法时,通常都需要重写hashCode()方法,
以便维护hashCode()方法的通用契约,该契约规定equal对象必须具有相等的哈希码。
- Java应用程序执行期间多次对同一个对象调用hashCode方法时,如果在对象相等比较中使用的信息没有被修改,该方法就必须返回相同的整数。
此整数不需要在应用程序的一次执行与同一应用程序的另一次执行之间保持一致。 - 如果根据equals(Object)方法两个对象相等,则在每个对象上调用hashCode方法返回结果必须一致。
- 如果根据equals(Object)方法,得到两个对象不相等,对每个对象上调用hashCode方法的返回值不做要求。
但是,应该意识到,为不相等的对象生成不同的整数结果可能会提高哈希表的性能。
- EqualsBuilder and HashCodeBuilder
Apache commons提供了两个优秀的实用工具类HashCodeBuilder和EqualsBuilder,用于生成哈希代码和equals方法:
// Employee.java
import org.apache.commons.lang3.builder.EqualsBuilder;
import org.apache.commons.lang3.builder.HashCodeBuilder;
public class Employee
{
private Integer id;
private String firstname;
private String lastName;
private String department;
//Setters and Getters
@Override
public int hashCode()
{
final int PRIME = 31;
return new HashCodeBuilder(getId()%2==0?getId()+1:getId(), PRIME).toHashCode();
}
@Override
public boolean equals(Object o) {
if (o == null)
return false;
if (o == this)
return true;
if (o.getClass() != getClass())
return false;
Employee e = (Employee) o;
return new EqualsBuilder().
append(getId(), e.getId()).
isEquals();
}
}
- Eclipse 创建 hashCode() and equals()
大多数编辑器也能够为您生成一些良好的结构。 例如,Eclipse IDE可以选择为您生成一个很好的hashCode()和equals()实现。
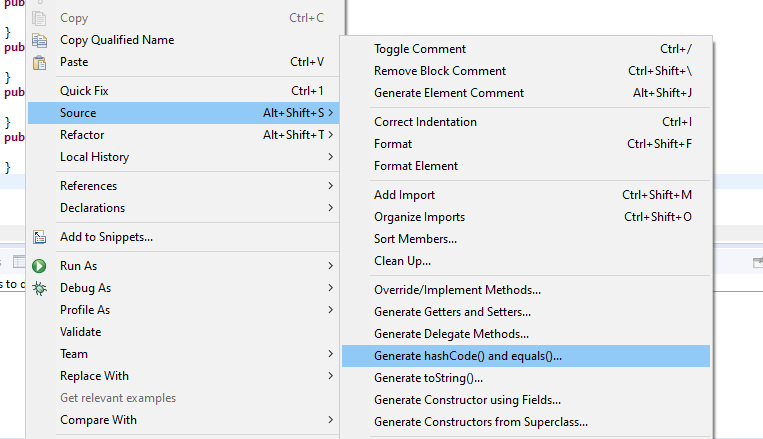
- 重写hashCode()和equals()时的注意点:
- 始终使用对象的相同属性来生成hashCode()和equals()两者。 上面我们使用了员工ID。
- equals 必须一致(如果对象未修改,则必须返回相同的值)。
- 每当a.equals(b)时,a.hashCode() 必须与b.hashCode() 相同。
- 如果重写了其中一个,则应同时重写另一个。
- 在ORM中使用时注意点
- 如果使用ORM,确保始终使用getter,并且永远不要在hashCode()和equals()中引用字段。
因为在ORM中,字段有时是延迟加载的,直到调用其getter方法才可用。
例如: 在Employee类中,如果使用e1.id == e2.id,id字段很可能是延迟加载的。
因此,在这种情况下,一个可能为零或null,从而导致错误的行为。
但是如果使用e1.getId() == e2.getId(),即使字段是延迟加载,也可以确保首先调用getter填充该字段。
# 解释所有访问修饰符?
private
default
默认访问级别是通过根本不写任何访问修饰符来声明的。
默认访问级别意味着 类本身的代码+与该类相同包内的类的代码 可以访问类、字段、构造函数或方法。
因此,默认访问修饰符有时也称为包访问修饰符。
public
protected
| Modifiers | Same Class | Same Package | Subclass | Other packages |
| public | Y | Y | Y | Y |
| protected | Y | Y | Y | N |
| default | Y | Y | N | N |
| private | Y | N | N | N |
# 什么是垃圾收集?可以强制执行吗?
垃圾收集是许多现代编程语言(比如Java语言和.net框架中的语言)的自动内存管理特性。
垃圾收集JVM虚拟机中解释或运行。
GC有两个目标:应该释放任何未使用的内存,除非程序不再使用它,否则不应该释放。
调用System.gc()可以向垃圾收集器提示希望它进行收集。
因为垃圾收集器是不确定的,所以没有办法强制和立即进行收集。
此外,在OutOfMemoryError的文档中声明,除非VM在进行了完整的垃圾收集后无法回收内存,否则不会抛出异常。
因此,如果一直分配内存直到内存溢出,将强制执行完整的垃圾收集。
[参考] :
Java Memory Management – Garbage Collection Algorithms
# 什么是native关键字?
native关键字应用于方法,以指示该方法是使用JNI在native代码中实现的。
即它标记一个方法,方法将在其他语言中实现,而不是在Java中。
过去使用native方法来编写性能关键部分,但随着Java越来越快,这种情况现在不太常见了。
现在需要native方法的场景:
- 需要从Java调用用其他语言编写的库。
- 实际上,许多与真实计算机交互的系统函数(例如磁盘和网络IO)只能这样做,因为它们调用了本地代码。
使用native代码库的缺点也很明显:
- JNI / JNA倾向于破坏JVM的稳定性,尤其是当尝试做一些复杂的事情时。
如果native代码错误地执行了native代码内存管理,则很有可能会使JVM崩溃。
如果你的native代码是不可重入的,并且从多个Java线程中调用,则坏事……会偶尔发生。 等等。 - 带有native代码的Java比纯Java或纯C / C ++更难调试。
- native代码可能为其他平台无关的Java应用程序引入重要的平台依赖性/问题。
- native代码需要一个单独的构建框架,并且也可能存在平台/可移植性问题。
# 什么是序列化?解释catches?
在计算机科学中,在数据存储和传输的环境中,序列化是将数据结构或对象状态转换成一种格式的过程,然后可以存储和恢复。
当根据序列化格式重新生成位序列时,可以使用它创建语义上相同的原始对象克隆。
Java提供了自动序列化,该序列化要求通过实现java.io.Serializable接口来标记对象。
实现该接口会将类标记为“可以序列化”,然后Java将在内部处理序列化。
在可序列化接口上没有定义任何序列化方法,但是可序列化的类可以选择定义带有某些特殊名称和签名的方法,
如果定义了这些特殊名称和签名,这些方法将被称为序列化/反序列化过程的一部分。
对象序列化后,其类中的更改会破坏反序列化过程。
要确定 class 中将来将兼容的变化和其他可能不兼容的变化,请在此处阅读完整的指南。
- 不兼容的更改
- 删除字段
- 将类的层级上移或下移
- 将非静态字段更改为静态或将 non-transient 字段更改为transient
- 更改原始字段的声明类型
- 更改writeObject或readObject方法,使其不再写入或读取默认字段数据
- 将类从可序列化更改为可外部化,反之亦然
- 将类从非枚举类型更改为枚举类型,反之亦然
- 删除可序列化或可外部化的
- 将writeReplace或readResolve方法添加到类
- 兼容的更改
- 添加字段
- 添加/移除类
- 添加writeObject / readObject方法(首先调用defaultReadObject或defaultWriteObject)
- 删除writeObject / readObject方法
- 添加java.io.Serializable
- 更改对字段的访问
- 将一个字段从静态更改为non-static 或从transient 更改为 non transient
# 1.2 对象初始化的最佳做法
在Java中,对象初始化被认为是一个很重的过程,你需要知道每个新创建的对象是如何影响内存和应用程序性能的。
一个简单的例子是Java包装类,它从外部看起来非常简单,就像原语一样,但实际上它们并没有看上去那么简单。
了解Java如何帮助你在包装类(如Double、Long或Integer)内部缓存对象。
# 1.3 HashMap 是如何工作的
# HashMap如何存储键值对?
# HashMap如何解决冲突?
# HashMap中如何使用hashCode()和equals()方法?
# key的随机/固定hashCode()值的影响?
# 在多线程环境中使用HashMap?
# 1.4 HashMap Key 好的设计
# 为什么String是HashMap的好钥匙?
# 如何设计一个用作键的类?
# 需要重写Key类中的hashCode()方法吗? 有什么影响?
# 为可以作为HashMap关键对象的类编写语法?
# 1.5 ConcurrentHashMap 相关问题
HashMap不是线程安全的。
可以在并发应用程序中使用HashTable,但是它会影响应用程序性能。
所以有ConcurrentHashMap,它是HashMap的并发版本,具有与HashMap相同的性能,同时也是线程安全的。
# 1.6 Java 集合框架 相关问题
# 解释 Collections 层次?
# 集和列表之间的区别?
# Vector和ArrayList之间的区别?
# HashMap和HashTable之间的区别?
# Iterator和ListIterator之间的区别?
# 为什么Map接口没有扩展Collection接口?
# 如何将String数组转换为ArrayList?
# 如何反转列表?
# HashSet如何存储元素?
# 是否可以将null元素添加到TreeSet或HashSet中?
# 什么是IdentityHashMap和WeakHashMap?
# 什么时候使用HashMap或TreeMap?
# 如何使 collection 只读?
# 如何使 collection 线程安全?
# fail-fast 和 fail-safe 之间有什么区别?
# 什么是 Comparable 和 Comparator 接口?
# 什么是Collections和Arrays类?
# 什么是队列和堆栈? 列出他们的差异?
# 1.7 什么是Java中的多态性
简而言之,多态就是我们可以创建在不同程序环境下表现不同的函数或引用变量的能力。
与继承,抽象和封装一样,多态是面向对象编程的主要构建块之一。
# 1.8 Java中的抽象是什么
# 1.9 抽象 和 封装
了解抽象和封装之间的区别是深入理解这两个概念的关键,不能孤立地学习两者。
# 1.10 接口和抽象类之间的区别?
Java 五分钟 - Interface & Abstract Class
自从Java语言诞生以来,就已经清晰地把抽象类和接口相分离。
但到了Java 8,发生了很多变化,它的核心概念之一是功能接口。
功能接口完全改变了我们看待Java语言的两个基本构建块的方式。
# 1.11 枚举的相关问题
Java 五分钟 - Enum 基础 Java 五分钟 - Enum 扩展知识
枚举已成为核心构建块很长时间了,在大多数流行的Java库中都可以看到它们。
它帮助你以更加面向对象的方式管理常量。
# 枚举与枚举类之间的区别?
# 枚举可以与String一起使用吗?
# 我们可以扩展枚举吗?
# 写枚举的语法?
# 如何在枚举中实现反向查找?
# 什么是EnumMap和EnumSet?
# 1.12 Java序列化和 Serializable 接口
# 什么是 serialVersionUID?
# 什么是 readObject 和 writeObject?
# 如何序列化和反序列化一个类?
# 要保证序列化不被打断,在对类进行更改时需要注意什么?
# 可以序列化静态字段吗?
# 1.13. Java Main 方法
# Java main 方法语法?
# 为什么main方法是 公有的(public)?
main方法是public,任何一个想要启动应用程序的对象在任何地方都可以访问它。
Java中的所有方法和构造函数都有一些访问修饰符,main()方法也需要一个。
请注意,如果不公开main()方法,则不会发生编译错误。
将出现运行时错误,因为不存在匹配的main()方法。
Main.java
public class Main
{
void static main(String[] args)
{
System.out.println("Hello World !!");
}
}
// Console
Error: Main method not found in class Main, please define the main method as:
public static void main(String[] args)
请记住,整个语法需要匹配才能执行main()方法。
# 为什么main方法是 静态的(static)?
假设main方法不是静态方法,要调用任何方法,需要它的一个实例。
众所周知,Java可以有重载的构造函数,JVM 就没法确定调用哪个 main 方法。
补充:
静态方法和静态数据加载到内存就可以直接调用而不需要像实例方法一样创建实例后才能调用,
如果 main 方法是静态的,那么它就会被加载到 JVM 上下文中成为可直接执行的方法。
- 请注意
如果不将main()方法设为静态,将发生运行时错误。
Main.java
public class Main
{
public void main(String[] args)
{
System.out.println("Hello World !!");
}
}
Error: Main method is not static in class main, please define the main method as:
public static void main(String[] args)
# 为什么main方法返回值是 void?
为什么返回值为void? 这样就不会返回一个无用的返回值给JVM。
应用程序要与调用过程进行通信的唯一一件事是:正常终止或异常终止。
使用System.exit(int)已经可以做到这一点。 非零值表示异常终止,否则一切正常。
# 为什么叫做main?
它已经在C和C++语言中使用了,所以,大多数开发人员已经习惯了这个名字。
否则,就没有其他好的理由了。
# 当调用main方法时,内部会发生什么?
Java中main方法的作用是作为程序执行的起点。
当你运行java.exe,然后有两个Java本机接口(JNI)调用。
这些调用会加载真正是JVM的DLL(是的-Java.exe不是JVM)。
JNI是我们在虚拟机世界和C,C ++等世界之间架起桥梁时所使用的工具,反之亦然。 如果不使用JNI,就不可能真正使JVM运行。
基本上,java.exe是一个超级简单的C应用程序,它解析命令行,在JVM中创建一个新的String数组来保存这些参数,
解析出你指定为包含main()的类名,使用JNI调用来查找 main() 方法本身,然后调用main() 方法,将新创建的字符串数组作为参数传入。
编写自己的java.exe版本(源代码随JDK分发)对你来说是完全合法的,并且可以让它执行完全不同的操作。
# 我们是否总是需要main方法来运行Java程序?
我相信不是,有不编写主方法的applet。
注:
- main() method native code in java.c
/*
* Get the application's main class.
*/
if (jarfile != 0) {
mainClassName = GetMainClassName(env, jarfile);
... ...
mainClass = LoadClass(env, classname);
if(mainClass == NULL) { /* exception occured */
... ...
/* Get the application's main method */
mainID = (*env)->GetStaticMethodID(env, mainClass, "main", "([Ljava/lang/String;)V");
... ...
{/* Make sure the main method is public */
jint mods;
jmethodID mid;
jobject obj = (*env)->ToReflectedMethod(env, mainClass, mainID, JNI_TRUE);
... ...
/* Build argument array */
mainArgs = NewPlatformStringArray(env, argv, argc);
if (mainArgs == NULL) {
ReportExceptionDescription(env);
goto leave;
}
/* Invoke main method. */
(*env)->CallStaticVoidMethod(env, mainClass, mainID, mainArgs);
# 1.14. Java 对象克隆
# clone()方法如何工作?
# Java中的浅拷贝是什么?
# 什么是复制构造函数?
# Java中的深拷贝是什么?
# 创建对象的深拷贝的不同方法?
# 1.15 什么是 CountDownLatch?
参考:Java concurrency – CountDownLatch Example
CountDownLatch是一种同步辅助工具,它允许一个或多个线程等待,直到在其他线程中执行的一组操作完成。
例如 应用程序的主线程要等待,直到负责启动框架服务的其他服务线程完成了所有服务的启动。
CountDownLatch与JDK 1.5一起引入,并与java.util.concurrent包中的其他并发实用程序
(如CyclicBarrier,Semaphore,ConcurrentHashMap和BlockingQueue)一起引入。
CountDownLatch的工作原理是用线程数初始化一个计数器,每当线程完成执行时,计数器的数量就会递减。
当count达到0时,意味着所有线程已经完成了它们的执行,等待锁存的线程继续执行。
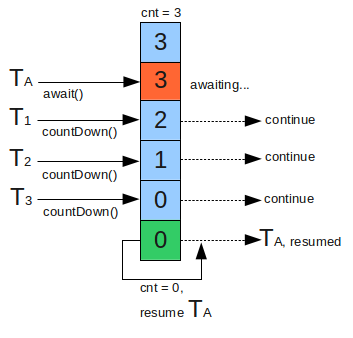
CountDownLatch的伪代码可以这样写:
//Main thread start
//Create CountDownLatch for N threads
//Create and start N threads
//Main thread wait on latch
//N threads completes there tasks are returns
//Main thread resume execution
# CountDownLatch 如何工作?
构造函数:
//Constructs a CountDownLatch initialized with the given count.
public CountDownLatch(int count) {...}
此计数本质上是闩锁应等待的线程数。
此值只能设置一次,并且CountDownLatch不提供其他任何机制来重置此计数。
CountDownLatch与主线程的第一次交互是等待其他线程。
这个主线程必须在启动其他线程之后立即调用 CountDownLatch.await()方法,
主线程执行将在await()方法上停止,直到其他线程完成它们的执行。
其他N个线程必须有闩锁对象的引用,因为它们需要通知CountDownLatch对象它们已经完成了任务。
这个通知是通过 CountDownLatch.countdown()方法完成的。
每次调用方法都会减少构造函数中设置的初始计数1。
因此,当所有N个线程都调用这个方法时,count达到0,主线程被允许在await()方法之后继续执行。
# CountDownLatch 的应用场景?
实现最大并行度
有时,我们希望同时启动多个线程,以实现最大的并行性。
例如,我们想测试一个类是否为单例。
如果我们创建一个初始计数为1的CountDownLatch,并让所有线程等待latch,这就很容易做到。
对countDown()方法的单个调用将在同一时间恢复所有等待线程的执行。等待N个线程完成,然后再开始执行
例如,一个应用程序启动类希望在处理用户请求之前确保所有N个外部系统都已启动并运行。死锁检测
一个非常方便的用例,你可以在每个测试阶段使用N个线程访问具有不同数量线程的共享资源,并尝试创建死锁。
# 1.16 为什么字符串是不可变的?
不变对象意味着对象的状态一旦初始化,就永远无法更改。
Java中的String类和wrapper类为不可变类。
接下来我们来回答为什么字符串是不可变的:
- 最重要的原因是安全性
Java类加载机制对作为参数传递的类名称起作用,然后在类路径中搜索这些类。
如果字符串是可变的,那么任何人都可以轻松地注入自己的类加载机制。 - 性能
String类的不可变性,使得字符串池发挥作用,提高了性能。 - 线程安全
不可变对象在多线程应用程序中的多个线程之间共享时是安全的。
# 1.17 怎样才能使得一个Java类不可变
通常,通过以下步骤可实现Java的不变性:
- 不要给类中的字段提供任何的赋值方法;
- 使所有字段为final 和 private;
- 不允许子类覆盖方法
最简单的方法是将类声明为final,Java中的final类无法被继承。 - 返回深拷贝的对象,其中包含类中所有可变字段的拷贝内容
永远记住,实例变量要么是可变的,要么是不可变的。
标识它们并为所有可变对象返回带有拷贝内容的新对象。
复杂巧妙的的方法是使构造函数私有,并在工厂方法中构造实例。
JDK中的不可变类:
String
Wrapper(包装类) Integer, Long, Double etc等 Immutable collection classes 如 Collections.singletonMap() 等. java.lang.StackTraceElement Java enums (理想情况下应该如此) java.util.Locale java.util.UUID使类不可变的好处
- 易于构建,测试和使用
- 自动是线程安全的,并且没有同步问题
- 不需要复制构造函数 do not need a copy constructor
- 不需要拷贝的实现 do not need an implementation of clone
- 允许hashCode*()使用延迟初始化,并缓存其返回值
- 用作字段时不需要防御性地拷贝
- 作为更好的Map Key 和Set元素(这些对象在集合中时不得更改状态)
- 在构造时就建立了其类不变式,因此无需再次检查
- 总是具有“失败原子性”( “failure atomicity”,约书亚·布洛赫(Joshua Bloch)使用的术语):
如果不可变的对象抛出异常,则永远不会处于不希望的状态或不确定的状态。